Examples¶
Introduction¶
This section demonstrate SIMPLE-NN with examples. Example files are in :gray:`SIMPLE-NN/examples/`. In this example, snapshots from 500K MD trajectory of amorphous SiO2 (60 atoms) are used as training set.
Note
Since we set the relative path for reference file in :gray:`str_list`, You need to move to the directory indicated in each section below to run the examples.
Generate NNP¶
To generate NNP using symmetry function and neural network, you need three types of input file (input.yaml, str_list, params_XX) as described in Tutorials section. The example files except params_Si and params_O are introduced below. Detail of params_Si and params_O can be found in Features section. Input files introduced in this section can be found in :gray:`SIMPLE-NN/examples/SiO2/generate_NNP`.
# input.yaml
generate_features: true
preprocess: true
train_model: true
atom_types:
- Si
- O
symmetry_function:
params:
Si: params_Si
O: params_O
neural_network:
method: Adam
nodes: 30-30
batch_size: 10
total_epoch: 50000
learning_rate: 0.001
# str_list
../ab_initio_output/OUTCAR_comp ::10
With this input file, SIMPLE-NN calculate feature vectors and its derivatives (:gray:`generate_features`), generate training/validation dataset (:gray:`preprocess`) and optimize the network (:gray:`train_model`). Sample VASP OUTCAR file (the file is compressed to reduce the file size) is in :gray:`SIMPLE-NN/examples/SiO2/ab_initio_output`. In MD trajectory, snapshots are sampled in the interval of 10 MD steps. In this example, 70 symmetry functions consist of 8 radial symmetry functions per 2-body combination and 18 angular symmetry functions per 3-body combination. Thus, this model uses 70-30-30-1 network for both Si and O. The network is optimized by Adam optimizer with the 0.001 of learning rate and batch size is 10.
Output files can be found in :gray:`SIMPLE-NN/examples/SiO2/generate_NNP/outputs`. In the folder, generated dataset is stored in :gray:`data` folder and execution log and energy/force RMSE are stored in :gray:`LOG`.
Potential test¶
Generate test dataset¶
Generating a test dataset is same as generating a training/validation dataset. In this example, we use same VASP OUTCAR to generate test dataset. Input files introduced in this section can be found in :gray:`SIMPLE-NN/examples/SiO2/generate_test_data`.
# input.yaml
generate_features: true
preprocess: true
train_model: false
atom_types:
- Si
- O
symmetry_function:
params:
Si: params_Si
O: params_O
valid_rate: 0.
In this case, :gray:`train_model` is set to :gray:`false` because training process is not required to generate test dataset. In addition, valid_rate also set to 0. :gray:`str_list` is same as Generate NNP section.
Note
To prevent overwriting of the existing training/validation dataset, create a new folder and create a test dataset.
Error check¶
To check the error for test dataset, use the setting below. And for running test mode, you need to copy the :gray:`train_list` file generated in Generate test dataset section to this folder and change filename to :gray:`test_list`. Input files introduced in this section can be found in :gray:`SIMPLE-NN/examples/SiO2/error_check`.
# input.yaml
generate_features: false
preprocess: false
train_model: true
atom_types:
- Si
- O
symmetry_function:
params:
Si: params_Si
O: params_O
neural_network:
method: Adam
nodes: 30-30
batch_size: 10
train: false
test: true
continue: true
Note
You need to change the filename from :gray:`SAVER_epochXXXX.*` to :gray:`SAVER.*` to use the option :gray:`continue: true` and modify the checkpoints file (remove ‘_epochXXXX’ in the text). If you use the option :gray:`continue: weights`, change the filename from :gray:`potential_saved_epochXXXX` to :gray:`potential_saved`.
After running SIMPLE-NN with the setting above, new output file named :gray:`test_result` is generated. The file is pickle format and you can open this file with python code of below:
from six.moves import cPickle as pickle
with open('test_result') as fil:
res = pickle.load(fil) # For Python 2
# res = pickle.load(fil, encoding='latin1') # For Python 3
In the file, DFT energies/forces, NNP energies/forces are included.
Parameter tuning¶
GDF¶
GDF [1] is used to reduce the force errors of the sparsely sampled atoms.
To use GDF, you need to calculate the 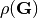 by adding the following lines to the :gray:`symmetry_function` section in :gray:`input.yaml`.
SIMPLE-NN supports automatic parameter generation scheme for
by adding the following lines to the :gray:`symmetry_function` section in :gray:`input.yaml`.
SIMPLE-NN supports automatic parameter generation scheme for 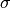 and
and  .
Use the setting :gray:`sigma: Auto` to get a robust and (values are stored in LOG file).
Input files introduced in this section can be found in
:gray:`SIMPLE-NN/examples/SiO2/parameter_tuning_GDF`.
.
Use the setting :gray:`sigma: Auto` to get a robust and (values are stored in LOG file).
Input files introduced in this section can be found in
:gray:`SIMPLE-NN/examples/SiO2/parameter_tuning_GDF`.
#symmetry_function:
#continue: true # if individual pickle file is not deleted
atomic_weights:
type: gdf
params:
sigma: Auto
# for manual setting
# Si: 0.02
# O: 0.02
indicates the density of each training point.
After calculating , histograms of 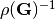 are also saved as in the file of :gray:`GDFinv_hist_XX.pdf`.
are also saved as in the file of :gray:`GDFinv_hist_XX.pdf`.
Note
If there is a peak in high region in the histogram,
increasing the Gaussian weight() is recommended until the peak is removed.
On the contrary, if multiple peaks are shown in low region in the histogram,
reduce is recommended until the peaks are combined.
In the default setting, the group of is scaled to have average value of 1.
The interval-averaged force error with respect to the
can be visualized with the following script.
from simple_nn.utils import graph as grp
grp.plot_error_vs_gdfinv(['Si','O'], 'test_result')
where :gray:`test_result` is generated after Error check as the output file.
The graph of interval-averaged force errors with respect to the
is generated as :gray:`ferror_vs_GDFinv_XX.pdf`
If default GDF is not sufficient to reduce the force error of sparsely sampled training points,
One can use scale function to increase the effect of GDF. In scale function,
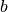 controls the decaying rate for low and
separates highly concentrated and sparsely sampled training points.
To use the scale function, add following lines to the :gray:`symmetry_function` section in :gray:`input.yaml`.
controls the decaying rate for low and
separates highly concentrated and sparsely sampled training points.
To use the scale function, add following lines to the :gray:`symmetry_function` section in :gray:`input.yaml`.
#symmetry_function:
weight_modifier:
type: modified sigmoid
params:
Si:
b: 0.02
c: 3500.
O:
b: 0.02
c: 10000.
For our experience, 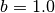 and automatically selected shows reasonable results.
To check the effect of scale function, use the following script for visualizing the
force error distribution according to .
In the script below, :gray:`test_result_noscale` is the test result file from the training without scale function and
:gray:`test_result_wscale` is the test result file from the training with scale function.
and automatically selected shows reasonable results.
To check the effect of scale function, use the following script for visualizing the
force error distribution according to .
In the script below, :gray:`test_result_noscale` is the test result file from the training without scale function and
:gray:`test_result_wscale` is the test result file from the training with scale function.
from simple_nn.utils import graph as grp
grp.plot_error_vs_gdfinv(['Si','O'], 'test_result_noscale', 'test_result_wscale')
| [1] | W. Jeong, K. Lee, D. Yoo, D. Lee and S. Han, J. Phys. Chem. C 122 (2018) 22790 |